Neural Rendering Colorful Cities
2025-11-04
As we increase the complexity of our representation, it is going to become harder for our model to solve the rendering problem. In an earlier post, we did a approximate calculation of the data space of the neural renderer. Every axis of variation we add to this further explodes our data requirements.
The next step is to extend the camera from a simple 1-axis of rotation view to a 2-degree-of-freedom camera. This is what is used in most traditional FPS games. We will pass our camera representation into the neural network as a 3D normalized vector direction. This has nicer properties than discontinuous yaw & pitch rotation values.
Results
Our current set-up is a 4-million parameter, feed-forward ReLU model. Our simple approach is to flatten the input shapes into a single vector. We lose position and rotation invariance and our training results are initially slower. By shifting to a RTX 5090 for training hardware we end up with reasonable training times:
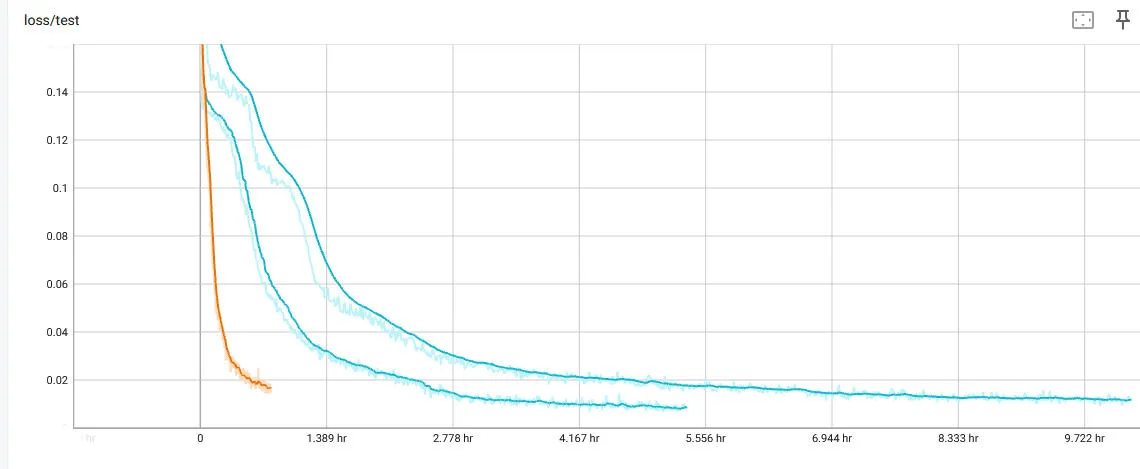
The variations in runs are due to differences in the CPU hardware. We render all the training data in real-time during training, headlessly. We therefore have no theoretical limit on the length of our training time.
We re-render our previous infinite color grid but with the new camera system. We can now look around. You can see on the horizon is a graying color. Despite longer training times this did not go away, which highlights a limitation of the size of our model.
Height Information
In addition to color, for each tile we can add a height value. Given our faster training times, we have some room to scale up the complexity of the problem. We make no changes to the model architecture. The model now has to deal with occlusions. We implement some nice dynamics where the height is zeroed if the player approaches a tile.
Further Ideas
Every pass of the neural network is a single-pixel render. Therefore we can render multiple scenes in a single pass. As long as an entire batch (size of the screen area) fits in memory, it is no additional cost to render multiple perspectives at once. Here is a demo rendering two worlds, one atop the other:
Finally, we use the baseline 32x32 resolution model to train a 64x64 render model. This is much more efficient than training a 64x64 model from scratch because the implicit pixel-based model design is already a good first guess for the scene, as can be scene by early predictions of the fine-tuned 32x32 resolution model:
2 training steps.
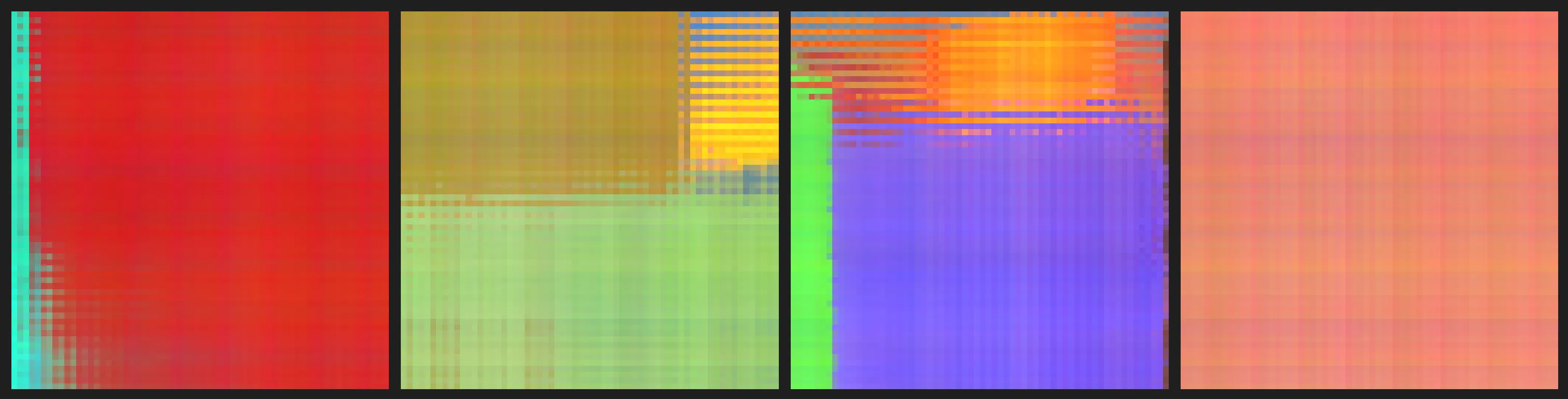 700 training steps.
700 training steps.
 12000 training steps.
12000 training steps.

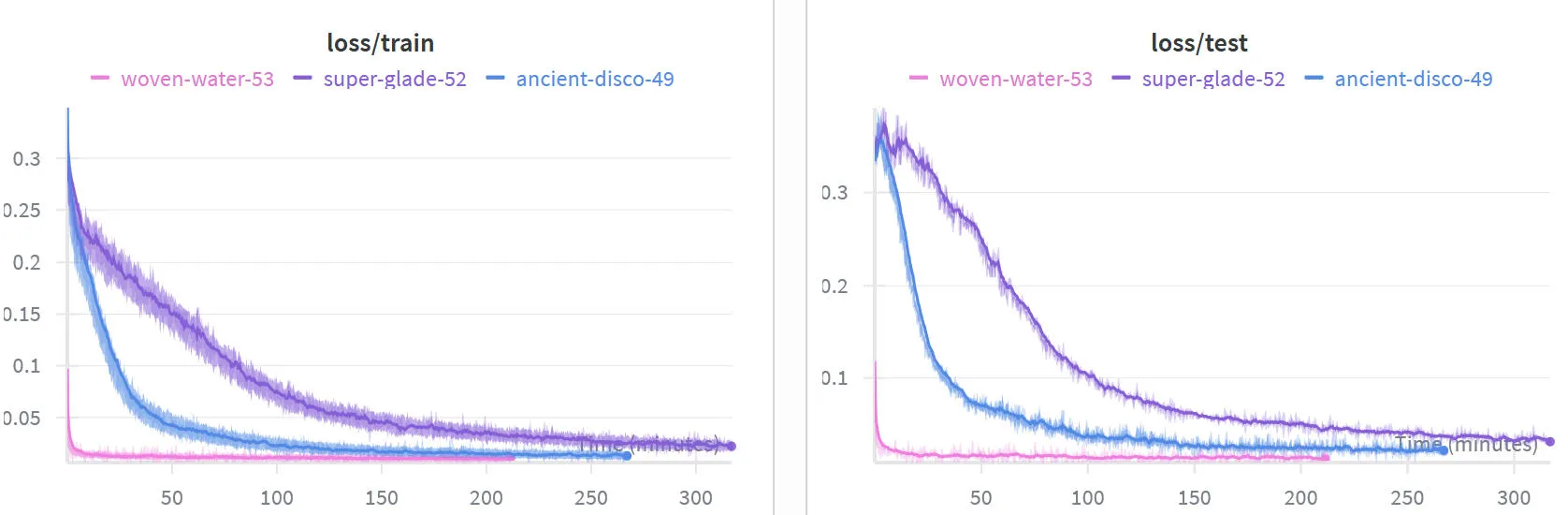
This plot shows the speed-up we gain. The blue line is the 32x32 training results, the purple line is the 64x64 training results, and the pink line is the fine-tuned 32x32 model for the 64x64 task. Fast!
And here is the video showcasing the higher-resolution which has a satisfying 'lumpiness' to it: